Medium-Sized Routed Network Construction
Routers can forward packets over static routes or dynamic routes, based on the router configuration. There are two ways to tell the router how to forward packets to networks that are not directly connected:
- Static: The router learns routes when an administrator manually configures the static route.
The administrator must manually update this static route entry whenever an internetwork topology change requires an update. Static routes are user-defined routes that specify the path that packets take when moving between a source and a destination. These administratordefined routes enable precise control over the routing behavior of the IP internetwork. - Dynamic: The router dynamically learns routes after an administrator configures a routing protocol that helps determine routes. Unlike the situation with static routes, after the network administrator enables dynamic routing, the routing process automatically updates route knowledge whenever new topology information is received. The router learns and maintains routes to the remote destinations by exchanging routing updates with other routers in the internetwork.
Dynamic routing relies on a routing protocol to disseminate knowledge. A routing protocol defines the rules that a router uses when it communicates with neighboring routers to determine paths to remote networks and maintains those networks in the routing tables. Figure 3-1 illustrates that a router in the network can have knowledge of networks that are not directly connected to an interface on that device. These routes must be configured statically or learned via routing protocols.
Figure 3-1 Routing Protocols

The following are the differences between a routed protocol and a routing protocol:
- Routed protocol: Any network protocol that provides enough information in its network layer address to enable a packet to be forwarded from one host to another host based on the addressing scheme, without knowing the entire path from source to destination. Packets generally are conveyed from end system to end system. IP is an example of a routed protocol.
- Routing protocol: Facilitates the exchange of routing information between networks, enabling routers to build routing tables dynamically. Traditional IP routing stays simple because it uses next-hop (next-router) routing, in which the router needs to consider only where it sends the packet and does not need to consider the subsequent path of the packet on the remaining hops (routers). Routing Information Protocol (RIP) is an example of a routing protocol.
Routing protocols describe the following information:- How updates are conveyed
- What knowledge is conveyed
- When to convey the knowledge
- How to locate recipients of the updates
You can classify dynamic routing protocols using many different methods. One method to classify a routing protocol is to determine if it is used to route in an autonomous system or between autonomous systems. An autonomous system is a collection of networks under a common administration that share a common routing strategy.
There are two types of routing protocols:
- Interior Gateway Protocols (IGP): These routing protocols exchange routing information within an autonomous system. Routing Information Protocol version 2 (RIPv2), Enhanced Interior Gateway Routing (EIGRP), and Open Shortest Path First (OSPF) are examples of IGPs.
- Exterior Gateway Protocols (EGP): These routing protocols are used to route between autonomous systems. Border Gateway Protocol (BGP) is the EGP of choice in networks today.
Figure 3-2 shows the logical separation of where an IGP operates and where an EGP operates.
Figure 3-2 IGP Versus EGP

NOTE The Internet Assigned Numbers Authority (IANA) assigns autonomous system numbers for many jurisdictions. Use of IANA numbering is required if your organization plans to use BGP. However, it is good practice to be aware of private versus public autonomous system numbering schema.
Within an autonomous system, most IGP routing can be further classified as conforming to one of the following algorithms:
- Distance vector: The distance vector routing approach determines the direction (vector) and distance (such as hops) to any link in the internetwork.
- Link-state: The link-state approach, which utilizes the shortest path first (SPF) algorithm, creates an abstraction of the exact topology of the entire internetwork, or at least of the partition in which the router is situated.
- Advanced distance vector: The advanced distance vector approach combines aspects of the link-state and distance vector algorithms. This is also sometimes referred to as a hybrid routing protocol.
There is no single best routing algorithm for all internetworks. All routing protocols provide the information differently.
Multiple routes to a destination can exist. When a routing protocol algorithm updates the routing table, the primary objective of the algorithm is to determine the best route to include in the table. Each distance vector routing protocol uses a different routing metric to determine the best route. The algorithm generates a number called the metric value for each path through the network. With the exception of BGP, the smaller the metric, the better the path. Metrics can be calculated based on a single characteristic of a path. More complex metrics can be calculated by combining several path characteristics. The metrics that routing protocols most commonly use are as follows:
- Hop count: The number of times that a packet passes through the output port of one router
- Bandwidth: The data capacity of a link; for instance, normally, a 10-Mbps Ethernet link is preferable to a 64-kbps leased line
- Delay: The length of time that is required to move a packet from source to destination
- Load: The amount of activity on a network resource, such as a router or link
- Reliability: Usually refers to the bit error rate of each network link
- Cost: A configurable value that on Cisco routers is based by default on the bandwidth of the interface
Figure 3-3 shows an example of multiple routes between two hosts and the way different routing protocols compute metrics.
Multiple routing protocols and static routes can be used at the same time. If there are several sources for routing information, an administrative distance value is used to rate the trustworthiness of each routing information source. By specifying administrative distance values, Cisco IOS Software can discriminate between sources of routing information.
An administrative distance is an integer from 0 to 255. A routing protocol with a lower administrative distance is more trustworthy than one with a higher administrative distance. As shown in Figure 3-4, if Router A receives a route to network 172.16.0.0 advertised by EIGRP and by OSPF at the same time, Router A would use the administrative distance to determine that EIGRP is more trustworthy.
Figure 3-3 Routing Protocol Metrics

Figure 3-4 Administrative Distance

Router A would then add the EIGRP route to the routing table because EIGRP is a more trusted routing source than OSPF. The administrative distance is an arbitrary value that Cisco IOS sets to handle cases when multiple routing protocols send information about the same routes. Table 3-1 shows the default administrative distance for selected routing information sources.
Table 3-1 Default Administrative Distance Values

If nondefault values are necessary, you can use Cisco IOS Software to configure administrative distance values on a per-router, per-protocol, and per-route basis.
Understanding Distance Vector Routing Protocols
Distance vector–based routing algorithms (also known as Bellman-Ford-Moore algorithms) pass periodic copies of a routing table from router to router and accumulate distance vectors. (Distance means how far, and vector means in which direction.) Regular updates between routers communicate topology changes.
Each router receives a routing table from its direct neighbor. For example, in Figure 3-5, Router B receives information from Router A. Router B adds a distance vector metric (such as the number of hops), increasing the distance vector. It then passes the routing table to its other neighbor, Router C. This same step-by-step process occurs in all directions between direct-neighbor routers. (This is also known as routing by rumor.)
Figure 3-5 Distance Vector Protocols

In this way, the algorithm accumulates network distances so that it can maintain a database of internetwork topology information. Distance vector algorithms do not allow a router to know the exact topology of an internetwork.
Route Discovery, Selection, and Maintenance
In Figure 3-6, the interface to each directly connected network is shown as having a distance of 0.
Figure 3-6 Routing Information Sources

As the distance vector network discovery process proceeds, routers discover the best path to nondirectly connected destination networks based on accumulated metrics from each neighbor. For example, Router A learns about other networks based on information it receives from Router B. Each of these other network entries in the routing table has an accumulated distance vector to show how far away that network is in the given direction.
When the topology in a distance vector protocol internetwork changes, routing table updates must occur. As with the network discovery process, topology change updates proceed step by step from router to router.
Distance vector algorithms call for each router to send its entire routing table to each of its adjacent or directly connected neighbors. Distance vector routing tables include information about the total path cost (defined by its metric) and the logical address of the first router on the path to each network it knows about.
When a router receives an update from a neighboring router, it compares the update to its own routing table. The router adds the cost of reaching the neighboring router to the path cost reported by the neighbor to establish the new metric. If the router learns about a better route (smaller total metric) to a network from its neighbor, the router updates its own routing table.
For example, if Router B in Figure 3-7 is one unit of cost from Router A, Router B would add 1 to all costs reported by Router A when Router B runs the distance vector processes to update its routing table. This would be maintained by the routers exchanging routing information in a timely manner through some update mechanism.
Figure 3-7 Maintaining Routes

Routing Loops
When you are maintaining the routing information, routing loops can occur if the slow convergence of the internetwork after a topology change causes inconsistent routing entries. The example presented in the next few pages uses a simple network design to convey the concepts. Later in this chapter, you look at how routing loops occur and are corrected in more complex network designs. Figure 3-8 illustrates how each node maintains the distance from itself to each possible destination network.
Figure 3-8 Maintaining Distance

Just before the failure of network 10.4.0.0, shown in Figure 3-9, all routers had consistent knowledge and correct routing tables. The network is said to have converged. For this example, the cost function is hop count, so the cost of each link is 1. Router C is directly connected to network 10.4.0.0, with a distance of 0. The path of Router A to network 10.4.0.0 is through Router B, with a hop count of 2.
Figure 3-9 Slow Convergence Produces Inconsistent Routing

When network 10.4.0.0 fails, Router C detects the failure and stops routing packets out its E0 interface. However, Routers A and B have not yet received notification of the failure. Router A still believes it can access 10.4.0.0 through Router B. The routing table of Router A still reflects a path to network 10.4.0.0 with a distance of 2.
Because the routing table of Router B indicates a path to network 10.4.0.0, Router C believes it has a viable path to network 10.4.0.0 through Router B. Router C updates its routing table to reflect a path to network 10.4.0.0 with a hop count of 2, as illustrated in Figure 3-10.
Figure 3-10 Inconsistent Path Information Between Routers

Because Routers A, B, and C conclude that the best path to network 10.4.0.0 is through each other, packets from Router A destined to network 10.4.0.0 continue to bounce between Routers B and C, as illustrated in Figure 3-12.
Router B receives a new update from Router C (3 hops). Router A receives the new routing table from Router B, detects the modified distance vector to network 10.4.0.0, and recalculates its own distance vector to 10.4.0.0 as 4, as shown in Figure 3-11.

Figure 3-12 Routing Loop Exists Because of Erroneous Hop Count

Continuing the example in Figure 3-12, the invalid updates about network 10.4.0.0 continue to loop. Until some other process can stop the looping, the routers update each other inappropriately, considering that network 10.4.0.0 is down.
This condition, called count-to-infinity, causes the routing protocol to continually increase its metric and route packets back and forth between the devices, despite the fundamental fact that the destination network, 10.4.0.0, is down. While the routing protocol counts to infinity, the invalid information enables a routing loop to exist, as illustrated in Figure 3-13.
Figure 3-13 Count-to-Infinity Condition

Without countermeasures to stop this process, the distance vector of hop count increments each time the routing update is broadcast to another router. This causes data packets to be sent through the network because of incorrect information in the routing tables. The following sections cover the countermeasures that distance vector routing protocols use to prevent routing loops from running indefinitely.
Troubleshooting Routing Loops with Maximum Metric Settings
IP packets have inherent limits via the Time-To-Live (TTL) value in the IP header. In other words, a router must reduce the TTL field by at least 1 each time it gets the packet. If the TTL value becomes 0, the router discards that packet. However, this does not stop the router from continuing to attempt to send the packet to a network that is down.
To avoid this prolonged problem, distance vector protocols define infinity as some maximum number. This number refers to a routing metric, such as a hop count. With this approach, the routing protocol permits the routing loop until the metric exceeds its maximum allowed value. Figure 3-14 shows this unreachable value as 16 hops. After the metric value exceeds the maximum, network 10.4.0.0 is considered unreachable.
Figure 3-14 Maximum Metric

Preventing Routing Loops with Split Horizon
One way to eliminate routing loops and speed up convergence is through the technique called split horizon. The split horizon rule is that sending information about a route back in the direction from which the original update came is never useful. For example, Figure 3-15 illustrates the following:
- Router B has access to network 10.4.0.0 through Router C. It makes no sense for Router B to announce to Router C that Router B has access to network 10.4.0.0 through Router C.
- Given that Router B passed the announcement of its route to network 10.4.0.0 to Router A, it makes no sense for Router A to announce its distance from network 10.4.0.0 to Router B.
- Having no alternative path to network 10.4.0.0, Router B concludes that network 10.4.0.0 is inaccessible.
Figure 3-15 Split Horizon

Preventing Routing Loops with Route Poisoning
Another operation complementary to split horizon is a technique called route poisoning. Route poisoning attempts to improve convergence time and eliminate routing loops caused by inconsistent updates. With this technique, when a router loses a link, the router advertises the loss of a route to its neighbor device. Route poisoning enables the receiving router to advertise a route back toward the source with a metric higher than the maximum. The advertisement back seems to violate split horizon, but it lets the router know that the update about the down network was received. The router that received the update also sets a table entry that keeps the network state consistent while other routers gradually converge correctly on the topology change. This
mechanism allows the router to learn quickly of the down route and to ignore other updates that might be wrong for the hold-down period. This prevents routing loops.
Figure 3-16 illustrates the following example. When network 10.4.0.0 goes down, Router C poisons its link to network 10.4.0.0 by entering a table entry for that link as having infinite cost (that is, being unreachable). By poisoning its route to network 10.4.0.0, Router C is not susceptible to incorrect updates from neighboring routers, which may still have an outdated entry for network 10.4.0.0.
Figure 3-16 Route Poisoning

When Router B sees the metric to 10.4.0.0 jump to infinity, it sends an update called a poison reverse to Router C, stating that network 10.4.0.0 is inaccessible, as illustrated in Figure 3-17. This is a specific circumstance overriding split horizon, which occurs to make sure that all routers on that segment have received information about the poisoned route.
Figure 3-17 Poison Reverse

Route Maintenance Using Hold-Down Timers
Hold-down timers prevent regular update messages from inappropriately reinstating a route that might have gone bad. Hold-downs tell routers to hold any changes that might affect routes for some period of time. The hold-down period is usually calculated to be just greater than the time necessary to update the entire network with a routing change.
Hold-down timers perform route maintenance as follows:
- When a router receives an update from a neighbor indicating that a previously accessible network is now inaccessible, the router marks the route as inaccessible and starts a hold-down timer.
- If an update arrives from a neighboring router with a better metric than originally recorded for the network, the router marks the network as accessible and removes the hold-down timer.
- If at any time before the hold-down timer expires, an update is received from a different neighboring router with a poorer metric, the update is ignored. Ignoring an update with a higher metric when a holddown is in effect enables more time for the knowledge of the change to propagate through the entire network.
- During the hold-down period, routes appear in the routing table as “possibly down.”
Figure 3-18 illustrates the hold-down timer process.
Figure 3-18 Hold-Down Timers

Route Maintenance Using Triggered Updates
In the previous examples, routing loops were caused by erroneous information calculated as a result of inconsistent updates, slow convergence, and timing. If routers wait for their regularly scheduled updates before notifying neighboring routers of network catastrophes, serious problems can occur, such as loops or traffic being dropped.
Normally, new routing tables are sent to neighboring routers on a regular basis. A triggered update is a new routing table that is sent immediately, in response to a change. The detecting router immediately sends an update message to adjacent routers, which, in turn, generate triggered updates notifying their adjacent neighbors of the change. This wave propagates throughout the portion of the network that was using the affected link. Figure 3-19 illustrates what takes place when using triggered updates.
Figure 3-19 Triggered Updates

Triggered updates would be sufficient with a guarantee that the wave of updates reached every appropriate router immediately. However, two problems exist:
- Packets containing the update message can be dropped or corrupted by some link in the network.
- The triggered updates do not happen instantaneously. A router that has not yet received the triggered update can issue a regular update at just the wrong time, causing the bad route to be reinserted in a neighbor that had already received the triggered update.
Coupling triggered updates with holddowns is designed to get around these problems. Route Maintenance Using Hold-Down Timers with Triggered Updates Because the hold-down rule says that when a route is invalid, no new route with the same or a higher metric will be accepted for the same destination for some period, the triggered update has time to propagate throughout the network.
The troubleshooting solutions presented in the previous sections work together to prevent routing loops in a more complex network design. As depicted in Figure 3-20, the routers have multiple routes to each other. As soon as Router B detects the failure of network 10.4.0.0, Router B removes its route to that network. Router B sends a trigger update to Routers A and D, poisoning the route to network 10.4.0.0 by indicating an infinite metric to that network.
Figure 3-20 Implementing Multiple Solutions

Routers D and A receive the triggered update and set their own hold-down timers, noting that the 10.4.0.0 network is “possibly down.” Routers D and A, in turn, send a triggered update to Router E, indicating the possible inaccessibility of network 10.4.0.0. Router E also sets the route to 10.4.0.0 in holddown. Figure 3-21 depicts the way Routers A, D, and E implement hold-down timers.
Figure 3-21 Route Fails

Router A and Router D send a poison reverse to Router B, stating that network 10.4.0.0 is inaccessible. Because Router E received a triggered update from Routers A and D, it sends a poison reverse to Routers A and D. Figure 3-22 illustrates the sending of poison reverse updates.
Figure 3-22 Route Holddown

Routers A, D, and E will remain in holddown until one of the following events occurs:
- The hold-down timer expires.
- Another update is received, indicating a new route with a better metric.
- A flush timer, which is the time a route will be held before being removed, removes the route from the routing table.
During the hold-down period, Routers A, D, and E assume that the network status is unchanged from its original state and attempt to route packets to network 10.4.0.0. Figure 3-23 illustrates Router E attempting to forward a packet to network 10.4.0.0. This packet will reach Router B. However, because Router B has no route to network 10.4.0.0, Router B will drop the packet and return an Internet Control Message Protocol (ICMP) network unreachable message.
Figure 3-23 Packets During Holddown

When the 10.4.0.0 network comes back up, Router B sends a trigger update to Routers A and D, notifying them that the link is active. After the hold-down timer expires, Routers A and D add route 10.4.0.0 back to the routing table as accessible, as illustrated in Figure 3-24.
Figure 3-24 Network Up

Routers A and D send Router E a routing update stating that network 10.4.0.0 is up, and Router E updates its routing table after the hold-down timer expires, as illustrated in Figure 3-25.
Figure 3-25 Network Converges

Link-State and Advanced Distance Vector Protocols
In addition to distance vector–based routing, the second basic algorithm used for routing is the link-state algorithm. Link-state protocols build routing tables based on a topology database. This database is built from link-state packets that are passed between all the routers to describe the state of a network. The shortest path first algorithm uses the database to build the routing table. Figure 3-26 shows the components of a link-state protocol.
Figure 3-26 Link-State Protocols

Understanding the operation of link-state routing protocols is critical to being able to enable, verify, and troubleshoot their operation.
Link-state-based routing algorithms—also known as shortest path first (SPF) algorithms— maintain a complex database of topology information. Whereas the distance vector algorithm has nonspecific information about distant networks and no knowledge of distant routers, a link-state routing algorithm maintains full knowledge of distant routers and how they interconnect.
Link-state routing uses link-state advertisements (LSA), a topological database, the SPF algorithm, the resulting SPF tree, and, finally, a routing table of paths and ports to each network. Open Shortest Path First (OSPF) and Intermediate System-to-Intermediate System (IS-IS) are classified as link-state routing protocols. RFC 2328 describes OSPF link-state concepts and operations. Link-state routing protocols collect routing information from all other routers in the network or within a defined area of the internetwork. After all the information is collected, each router, independently of the other routers, calculates its best paths to all destinations in the network. Because each router maintains its own view of the network, it is less likely to propagate incorrect information provided by any one particular neighboring router.
Link-state routing protocols were designed to overcome the limitations of distance vector routing protocols. Link-state routing protocols respond quickly to network changes, send triggered updates only when a network change has occurred, and send periodic updates (known as link-state refreshes) at long intervals, such as every 30 minutes. A hello mechanism determines the reachability of neighbors.
When a failure occurs in the network, such as a neighbor becomes unreachable, link-state protocols flood LSAs using a special multicast address throughout an area. Each link-state router takes a copy of the LSA, updates its link-state (topological) database, and forwards the LSA to all neighboring devices. LSAs cause every router within the area to recalculate routes. Because LSAs need to be flooded throughout an area and all routers within that area need to recalculate their routing tables, you should limit the number of link-state routers that can be in an area.
A link is similar to an interface on a router. The state of the link is a description of that interface and of its relationship to its neighboring routers. A description of the interface would include, for example, the IP address of the interface, the mask, the type of network to which it is connected, the routers connected to that network, and so on. The collection of link states forms a link-state, or topological, database. The link-state database is used to calculate the best paths through the network. Link-state routers find the best paths to a destination by applying Dr. Edsger Dijkstra’s SPF algorithm against the link-state database to build the SPF tree. The best paths are then selected from the SPF tree and placed in the routing table.
As networks become larger in scale, link-state routing protocols become more attractive for the following reasons:
- Link-state protocols always send updates when a topology changes.
- Periodic refresh updates are more infrequent than for distance vector protocols.
- Networks running link-state routing protocols can be segmented into area hierarchies, limiting the scope of route changes.
- Networks running link-state routing protocols support classless addressing.
- Networks running link-state routing protocols support route summarization.
Link-state protocols use a two-layer network hierarchy, as shown in Figure 3-27.
Figure 3-27 Link-State Network Hierarchy

The two-layer network hierarchy contains two primary elements:
- Area: An area is a grouping of networks. Areas are logical subdivisions of the autonomous system (AS).
- Autonomous system: An AS consists of a collection of networks under a common administration that share a common routing strategy. An AS, sometimes called a domain, can be logically subdivided into multiple areas.
Within each AS, a contiguous backbone area must be defined. All other nonbackbone areas are connected off the backbone area. The backbone area is the transition area because all other areas communicate through it. For OSPF, the nonbackbone areas can be additionally configured as a stub area, a totally stubby area, a not-so-stubby area (NSSA), or a totally not-so-stubby area to help reduce the link-state database and routing table size.
Routers operating within the two-layer network hierarchy have different routing entities. The terms used to refer to these entities are different for OSPF than IS-IS. Refer to the following examples from Figure 3-27:
- Router A is called the backbone router in OSPF and the L2 router in IS-IS. The backbone, or L2, router provides connectivity between different areas.
- Routers B and C are called area border routers (ABR) in OSPF, and L1/L2 routers in IS-IS. ABR, or L1/L2, routers attach to multiple areas, maintain separate link-state databases for each area to which they are connected, and route traffic destined for or arriving from other areas.
- Routers D and E are called nonbackbone internal routers in OSPF, or L1 routers in IS-IS. Nonbackbone internal, or L1, routers are aware of the topology within their respective areas and maintain identical link-state databases about the areas.
- The ABR, or L1/L2, router will advertise a default route to the nonbackbone internal, or L1, router. The L1 router will use the default route to forward all interarea or interdomain traffic to the ABR, or L1/L2, router. This behavior can be different for OSPF, depending on how the OSPF nonbackbone area is configured (stub area, totally stubby area, or not-so-stubby area).
Link-State Routing Protocol Algorithms
Link-state routing algorithms, known collectively as SPF protocols, maintain a complex database of the network topology. Unlike distance vector protocols, link-state protocols develop and maintain full knowledge of the network routers and how they interconnect. This is achieved through the exchange of link-state packets (LSP) with other routers in a network.
Each router that has exchanged LSPs constructs a topological database using all received LSPs. An SPF algorithm is then used to compute reachability to networked destinations. This information is employed to update the routing table. The process can discover changes in the network topology caused by component failure or network growth.
In fact, the LSP exchange is triggered by an event in the network, instead of running periodically. This can greatly speed up the convergence process because it is unnecessary to wait for a series of timers to expire before the networked routers can begin to converge.
If the network shown in Figure 3-28 uses a link-state routing protocol, connectivity between New York City and San Francisco is not a concern. Depending on the actual protocol employed and the metrics selected, it is highly likely that the routing protocol could discriminate between the two paths to the same destination and try to use the best one.
Figure 3-28 Link-State Algorithms

Table 3-2 summarizes the contents of the routing database of each router in the figure.
Table 3-2 Link-State Routing Database
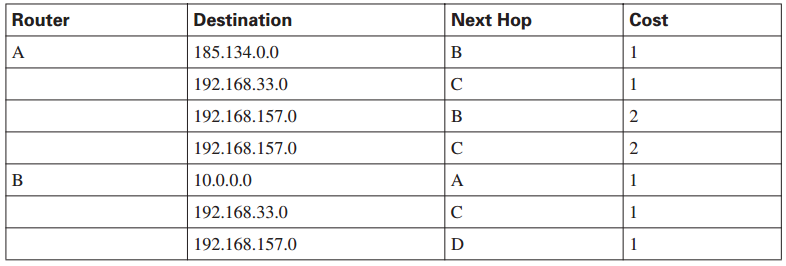
continues

As shown in the table link-state database entries for the New York (Router A) to Los Angeles (Router D) routes, a link-state protocol would remember both routes. Some link-state protocols can even provide a way to assess the performance capabilities of these two routes and bias toward the better-performing one. If the better-performing path, such as the route through Boston (Router C), experienced operational difficulties of any kind, including congestion or component failure, the link-state routing protocol would detect this change and begin forwarding packets through San Francisco (Router B). Link-state routing might flood the network with LSPs during initial topology discovery and can be both memory- and processor-intensive. This section describes the benefits of link-state routing, the caveats to consider when using it, and the potential problems.
The following list highlights some of the many benefits that link-state routing protocols have over the traditional distance vector algorithms, such as RIP-1 or the now obsolete Interior Gateway Routing Protocol (IGRP):
- Link-state protocols use cost metrics to choose paths through the network. For Cisco IOS devices, the cost metric reflects the capacity of the links on those paths.
- By using triggered, flooded updates, link-state protocols can immediately report changes in the network topology to all routers in the network. This immediate reporting generally leads to fast convergence times.
- Because each router has a complete and synchronized picture of the network, it is difficult for routing loops to occur.
- Because LSPs are sequenced and aged, routers always base their routing decisions on the latest set of information.
- With careful network design, the link-state database sizes can be minimized, leading to smaller SPF calculations and faster convergence.
The link-state approach to dynamic routing can be useful in networks of any size. In a welldesigned network, a link-state routing protocol enables your network to gracefully adapt to unexpected topology changes. Using events, such as changes, to drive updates, rather than fixedinterval timers, enables convergence to begin that much more quickly after a topological change.
The overhead of the frequent, time-driven updates of a distance vector routing protocol is also avoided. This makes more bandwidth available for routing traffic rather than for network maintenance, provided you design your network properly.
A side benefit of the bandwidth efficiency of link-state routing protocols is that they facilitate network scalability better than either static routes or distance vector protocols. When compared to the limitations of static routes or distance vector protocols, you can easily see that link-state routing is best in larger, more complex networks, or in networks that must be highly scalable. Initially configuring a link-state protocol in a large network can be challenging, but it is well worth the effort in the long run. Link-state protocols do, however, have the following limitations:
- They require a topology database, an adjacency database, and a forwarding database, in addition to the routing table. This can require a significant amount of memory in large or complex networks.
- Dijkstra’s algorithm requires CPU cycles to calculate the best paths through the network. If the network is large or complex (that is, the SPF calculation is complex), or if the network is unstable (that is, the SPF calculation is running on a regular basis), link-state protocols can use significant CPU power.
- To avoid excessive memory or CPU power, a strict hierarchical network design is required, dividing the network into smaller areas to reduce the size of the topology tables and the length of the SPF calculation. However, this dividing can cause problems because areas must remain contiguous at all times. The routers in an area must always be capable of contacting and receiving LSPs from all other routers in their area. In a multiarea design, an area router must always have a path to the backbone, or it will have no connectivity to the rest of the network. In addition, the backbone area must remain connected at all times to avoid some areas becoming isolated (partitioned).
- The configuration of link-state networks is usually simple, provided that the underlying network architecture has been soundly designed. If the network design is complex, the operation of the link-state protocol might have to be tuned to accommodate it.
- During the initial discovery process, link-state routing protocols can flood the network with LSPs and significantly decrease the capability of the network to transport data because no traffic is passed until after the initial network convergence. This performance compromise is temporary but can be noticeable. Whether this flooding process will noticeably degrade network performance depends on two things: the amount of available bandwidth and the number of routers that must exchange routing information. Flooding in large networks with relatively small links, such as low-bandwidth links, is much more noticeable than a similar exercise on a small network with large links, such as T3s and Ethernet.
- Link-state routing is both memory- and processor-intensive. Consequently, more fully configured routers are required to support link-state routing than distance vector routing. This increases the cost of the routers that are configured for link-state routing.
The following are some of the benefits of a link-state routing protocol: - Troubleshooting is usually easier in link-state networks because every router has a complete copy of the network topology, or at least of its own area of the network. However, interpreting the information stored in the topology, neighbor databases, and routing table requires an understanding of the concepts of link-state routing.
- Link-state protocols usually scale to larger networks than distance vector protocols, particularly the traditional distance vector protocols such as RIPv1 and IGRP. You can address and resolve the potential performance impacts of both drawbacks through foresight, planning, and engineering.
Advanced Distance Vector Protocol Algorithm
The advanced distance vector protocol, or hybrid routing protocol, uses distance vectors with more accurate metrics to determine the best paths to destination networks. However, it differs from most distance vector protocols by using topology changes to trigger routing database updates, as opposed to periodic updates.
This routing protocol converges more rapidly, like the link-state protocols. However, it differs from link-state protocols by emphasizing economy in the use of required resources, such as bandwidth, memory, and processor overhead. An example of an advanced distance vector protocol is the Cisco Enhanced Interior Gateway Routing Protocol (EIGRP).
Implementing Variable-Length Subnet Masks
Variable-length subnet masks (VLSM) were developed to enable multiple levels of subnetworked IP addresses within a single network. This strategy can be used only when it is supported by the routing protocol in use, such as Routing Information Protocol version 2 (RIPv2), OSPF, and EIGRP. VLSM is a key technology on large, routed networks. Understanding its capabilities is important when planning large networks.
Reviewing Subnets
Prior to working with VLSM, it is important to have a firm grasp on IP subnetting. When you are creating subnets, you must determine the optimal number of subnets and hosts.
Computing Usable Subnetworks and Hosts
Remember that an IP address has 32 bits and comprises two parts: a network ID and a host ID. The length of the network ID and host ID depends on the class of the IP address. The number of hosts available also depends on the class of the IP address. The default number of bits in the network ID is referred to as the classful prefix length. Therefore, a Class C address has a classful prefix length of /24, a Class B address has a classful prefix length of /16, and a Class A address has a classful prefix length of /8. This is illustrated in Figure 3-29.
Figure 3-29 Classful Prefix Length

The subnet address is created by taking address bits from the host-number portion of Class A, Class B, and Class C addresses. Usually a network administrator assigns the subnet address locally. Like IP addresses, each subnet address must be unique.
Each time one bit is borrowed from a host field, one less bit remains in the host field that can be used for host numbers, and the number of host addresses that can be assigned per subnet decreases by a power of 2.
When you borrow bits from the host field, note the number of additional subnets that are being created each time one more bit is borrowed. Borrowing two bits creates four possible subnets (22 = 4). Each time another bit is borrowed from the host field, the number of possible subnets increases by a power of 2, and the number of individual host addresses decreases by a power of 2. The following are examples of how many subnets are available, based on the number of host bits that you borrow:
- Using 3 bits for the subnet field results in 8 possible subnets (23 = 8).
- Using 4 bits for the subnet field results in 16 possible subnets (24 = 16).
- Using 5 bits for the subnet field results in 32 possible subnets (25 = 32).
- Using 6 bits for the subnet field results in 64 possible subnets (26 = 64).
In general, you can use the following formula to calculate the number of usable subnets, given the number of subnet bits used: Number of subnets = 2s (in which s is the number of subnet bits)
For example, you can subnet a network with a private network address of 172.16.0.0/16 so that it provides 100 subnets and maximizes the number of host addresses for each subnet. The following list highlights the steps required to meet these needs:
- How many bits will need to be borrowed?
- 2s = 27 = 128 subnets (s = 7 bits)
- What is the new subnet mask?
- Borrowing 7 host bits = 255.255.254.0 or /23
- What are the first four subnets?
- 172.16.0.0, 172.16.2.0, 172.16.4.0, and 172.16.6.0
- What are the ranges of host addresses for the four subnets?
- 172.16.0.1–172.16.1.254
- 172.16.2.1–172.16.3.254
- 172.16.4.1–172.16.5.254
- 172.16.6.1–172.16.7.254
Introducing VLSMs
When an IP network is assigned more than one subnet mask for a given major network, it is considered a network with VLSMs, overcoming the limitation of a fixed number of fixed-size subnetworks imposed by a single subnet mask. Figure 3-30 shows the 172.16.0.0 network with four separate subnet masks.
Figure 3-30 VLSM Network

VLSMs provide the capability to include more than one subnet mask within a network and the capability to subnet an already subnetted network address. In addition, VLSM offers the following benefits:
- Even more efficient use of IP addresses: Without the use of VLSMs, companies must implement a single subnet mask within an entire Class A, B, or C network number. For example, consider the 172.16.0.0/16 network address divided into subnets using /24 masking, and one of the subnetworks in this range, 172.16.14.0/24, further divided into smaller subnets with the /27 masking, as shown in Figure 3-30. These smaller subnets range from 172.16.14.0/27 to 172.16.14.224/27. In the figure, one of these smaller subnets, 172.16.14.128/27, is further divided with the /30 prefix, creating subnets with only two hosts to be used on the WAN links. The /30 subnets range from 172.16.14.128/30 to 172.16.14.156/30. In Figure 3-30, the WAN links used the 172.16.14.132/30, 172.16.14.136/30, and 172.16.14.140/30 subnets out of the range.
- Greater capability to use route summarization: VLSM allows more hierarchical levels within an addressing plan, allowing better route summarization within routing tables. For example, in Figure 3-30, subnet 172.16.14.0/24 summarizes all the addresses that are further subnets of 172.16.14.0, including those from subnet 172.16.14.0/27 and from 172.16.14.128/30.
As already discussed, with VLSMs, you can subnet an already subnetted address. Consider, for example, that you have a subnet address 172.16.32.0/20, and you need to assign addresses to a network that has ten hosts. With this subnet address, however, you have more than 4000 (212 – 2 = 4094) host addresses, most of which will be wasted. With VLSMs, you can further subnet the address 172.16.32.0/20 to give you more network addresses and fewer hosts per network. If, for example, you subnet 172.16.32.0/20 to 172.16.32.0/26, you gain 64 (26) subnets, each of which could support 62 (26 – 2) hosts.
Figure 3-31 shows how subnet 172.16.32.0/20 can be divided into smaller subnets.

The following procedure shows how to further subnet 172.16.32.0/20 to 172.16.32.0/26:
Step 1 Write 172.16.32.0 in binary form.
Step 2 Draw a vertical line between the twentieth and twenty-first bits, as shown in Figure 3-31. (/20 was the original subnet boundary.)
Step 3 Draw a vertical line between the twenty-sixth and twenty-seventh bits, as shown in the figure. (The original /20 subnet boundary is extended six bits to the right, becoming /26.)
Step 4 Calculate the 64 subnet addresses using the bits between the two vertical lines, from lowest to highest in value. Figure 3-31 shows the first five subnets available.
VLSMs are commonly used to maximize the number of possible addresses available for a network. For example, because point-to-point serial lines require only two host addresses, using a /30 subnet will not waste scarce IP addresses.
In Figure 3-32, the subnet addresses used on the Ethernets are those generated from subdividing the 172.16.32.0/20 subnet into multiple /26 subnets. The figure illustrates where the subnet addresses can be applied, depending on the number of host requirements. For example, the WAN links use subnet addresses with a prefix of /30. This prefix allows for only two hosts: just enough hosts for a point-to-point connection between a pair of routers.
Figure 3-32 VLSM Example

To calculate the subnet addresses used on the WAN links, further subnet one of the unused /26 subnets. In this example, 172.16.33.0/26 is further subnetted with a prefix of /30. This provides four more subnet bits, and therefore 16 (24) subnets for the WANs.
NOTE Remember that only subnets that are unused can be further subnetted. In other words, if you use any addresses from a subnet, that subnet cannot be further subnetted. In the example, four subnet numbers are used on the LANs. Another unused subnet, 172.16.33.0/26, is further subnetted for use on the WANs.
Route Summarization with VLSM
In large internetworks, hundreds or even thousands of network addresses can exist. In these environments, it is often not desirable for routers to maintain many routes in their routing table. Route summarization, also called route aggregation or supernetting, can reduce the number of routes that a router must maintain by representing a series of network numbers in a single summary address. This section describes and provides examples of route summarization, including implementation considerations.
Figure 3-33 shows that Router A can either send three routing update entries or summarize the addresses into a single network number.
Figure 3-33 VLSM Route Summarization

The figure illustrates a summary route based on a full octet: 172.16.25.0/24, 172.16.26.0/24, and
172.16.27.0/24 could be summarized into 172.16.0.0/16.
NOTE Router A can route to network 172.16.0.0/16, including all subnets of that network. However, if there were other subnets of 172.16.0.0 elsewhere in the network (for example, if 172.16.0.0 were discontiguous), summarizing in this way might not be valid. Discontiguous networks and summarization are discussed later in this chapter.
Another advantage to using route summarization in a large, complex network is that it can isolate topology changes from other routers. That is, if a specific link in the 172.16.27.0/24 domain were “flapping,” or going up and down rapidly, the summary route would not change. Therefore, no router external to the domain would need to keep modifying its routing table due to this flapping activity. By summarizing addresses, you also reduce the amount of memory consumed by the routing protocol for table entries.
Route summarization is most effective within a subnetted environment when the network addresses are in contiguous blocks in powers of two. For example, 4, 16, or 512 addresses can be represented by a single routing entry because summary masks are binary masks—just like subnet masks—so summarization must take place on binary boundaries (powers of two).
Routing protocols summarize or aggregate routes based on shared network numbers within the network. Classless routing protocols, such as RIP-2, OSPF, IS-IS, and EIGRP, support route summarization based on subnet addresses, including VLSM addressing. Classful routing protocols, such as RIP-1 and IGRP, automatically summarize routes on the classful network boundary and do not support summarization on any other boundaries.
RFC 1518, “An Architecture for IP Address Allocation with CIDR,” describes summarization in full detail. Suppose a router receives updates for the following routes:
- 172.16.168.0/24
- 172.16.169.0/24
- 172.16.170.0/24
- 172.16.171.0/24
- 172.16.172.0/24
- 172.16.173.0/24
- 172.16.174.0/24
- 172.16.175.0/24
To determine the summary route, the router determines the number of highest-order bits that match in all the addresses. By converting the IP addresses to the binary format, as shown in Figure 3-34, you can determine the number of common bits shared among the IP addresses.
Figure 3-34 Summarizing Within an Octet

In Figure 3-34, the first 21 bits are in common among the IP addresses. Therefore, the best summary route is 172.16.168.0/21. You can summarize addresses when the number of addresses is a power of two. If the number of addresses is not a power of two, you can divide the addresses into groups and summarize the groups separately.
To allow the router to aggregate the highest number of IP addresses into a single route summary, your IP addressing plan should be hierarchical in nature. This approach is particularly important when using VLSMs.
A VLSM design allows for maximum use of IP addresses, as well as more efficient routing update communication when using hierarchical IP addressing. In Figure 3-35, for example, route summarization occurs at two levels.
- Router C summarizes two routing updates from networks 172.16.32.64/26 and 172.16.32.128/26 into a single update, 172.16.32.0/24.
- Router A receives three different routing updates but summarizes them into a single routing update before propagating it to the corporate network.
Figure 3-35 Summarizing Addresses in a VLSM-Designed Network

Route summarization reduces memory use on routers and routing protocol network traffic. Requirements for summarization to work correctly are as follows:
- Multiple IP addresses must share the same highest-order bits.
- Routing protocols must base their routing decisions on a 32-bit IP address and a prefix length that can be up to 32 bits.
- Routing protocols must carry the prefix length (subnet mask) with the 32-bit IP address. Cisco routers manage route summarization in two ways:
- Sending route summaries: Routing protocols, such as RIP and EIGRP, perform automatic route summarization across network boundaries. Specifically, this automatic summarization occurs for those routes whose classful network address differs from the major network address of the interface to which the advertisement is being sent. For OSPF and IS-IS, you must configure manual summarization. For EIGRP and RIP-2, you can disable automatic route summarization and configure manual summarization. Whether routing summarization is automatic or not depends on the routing protocol. It is recommended that you review the documentation for your specific routing protocols. Route summarization is not always a solution. You would not use route summarization if you needed to advertise all networks across a boundary, such as when you have discontiguous networks.
- Selecting routes from route summaries: If more than one entry in the routing table matches a particular destination, the longest prefix match in the routing table is used. Several routes might match one destination, but the longest matching prefix is used.
For example, if a routing table has different paths to 192.16.0.0/16 and to 192.16.5.0/24, packets addressed to 192.16.5.99 would be routed through the 192.16.5.0/24 path because that address has the longest match with the destination address.
Classful routing protocols summarize automatically at network boundaries. This behavior, which cannot be changed with RIP-1 and IGRP, has important results, as follows:
- Subnets are not advertised to a different major network.
- Discontiguous subnets are not visible to each other.
In Figure 3-36, RIP-1 does not advertise the 172.16.5.0 255.255.255.0 and 172.16.6.0 255.255.255.0 subnets because RIPv1 cannot advertise subnets; both Router A and Router B advertise 172.16.0.0. This leads to confusion when routing across network 192.168.14.0. In this example, Router C receives routes about 172.16.0.0 from two different directions, so it cannot make a correct routing decision.
Figure 3-36 Classful Summarization in Discontiguous Networks

You can resolve this situation by using RIP-2, OSPF, IS-IS, or EIGRP and not using summarization because the subnet routes would be advertised with their actual subnet masks. For example:
NOTE Cisco IOS Software also provides an IP unnumbered feature that permits discontiguous subnets to be separated by an unnumbered link.
More Resources